Wenn eine Panne auftritt oder Funktionsstörungen festgestellt werden, ist die Suche nach der Ursache häufig kompliziert. Deshalb integriert BlueMind 3.5.9 künftig einen kompletten (Open-Source-)Stack von Metriken, Alerts und Zustandsanzeigen der Plattform.
Ein BlueMind-System bzw. ein Mail-Server im Allgemeinen ist ein komplexes System. Es umfasst zahlreiche Komponenten mit fest umrissenen, aber manchmal unverständlichen Rollen. Wenn eine Panne auftritt oder Funktionsstörungen festgestellt werden, ist die Suche nach der Ursache häufig kompliziert.
Eine Panne des E-Mail-Systems sorgt oft für Aufregung, da der Dienst für die Mehrzahl der Benutzer sehr wichtig ist. Dann werden Notfallmaßnahmen ergriffen, die häufig zu Neustarts führen und (manchmal) das Problem lösen, aber die Post-Mortem-Analyse deutlich erschweren.
Bestandsaufnahme
Ein BlueMind-System, das aus mehreren Diensten und zahlreichen virtuellen Java-Computern (JVM) besteht, versucht meistens, nicht stumm aus dem Leben zu scheiden.
Man wird folgende Dateien vorfinden:
• Dateien /var/log/java_pid1234.hprof; Speicherabbilder, die automatisch erstellt werden, wenn das System eine Speicherknappheit erkennt
• Zahlreiche Protokolldateien, in denen man so hässliche Dinge wie Elastiscsearch-Indizes findet, die uns „disk high watermark reached, disabling shards“ (die Festplatte ist voll) melden
In all diesen Fällen wird das Problem nicht sofort behandelt, und vor der Meldung einer Anomalie zur Analyse wird ein Neustart oder eine Bereinigung der Festplatte erfolgen.
Für einen Systemverwalter ist es kein Ruhmesblatt, wenn er zulässt, dass sich eine Festplatte füllt. Es entsteht die folgende Situation: Der Systemverwalter bereinigt die Festplatte und meldet anschließend eine Anomalie, um deutlich zu machen, dass die Suche nicht mehr zweckmäßig ist.

Diese kleine Lüge ist problematisch, aber was uns interessiert, ist die Frage, wie wir diese Situation vermeiden können.
Monitoring
Die Monitoring-Systeme sind vorhanden, aber ihre Bereitstellung wurde bisher den Personen überlassen, die für das Monitoring der BlueMind-Installationen zuständig sind. Das Monitoring der Java-Systeme ist ein recht komplexes Thema, und die allgemeinen Metriken sind weder interessant noch aussagekräftig.
Mit BlueMind 3.5.9 haben wir einen kompletten Stack von Metriken, Alerts und Zustandsanzeigen der Plattform integriert.
Da Open Source in unserer DNA angelegt ist, haben wir uns einer Open-Source-Lösung zugewendet: dem TICK-Stack (Telegraf, Influxdb, Chronograf, Kapacitor) http://influxdata.com. Ein Telegraf-Agent ist auf jedem Knoten Ihrer Anlage installiert. Telegraf übermittelt diese Daten an Influxdb. Kapacitor analysiert sie dann, um Alerts zu erstellen, und Chronograf zeigt Dashboards an, um die Antizipation von Problemen zu unterstützen.
Unsere Integration
Für die Version 3.5.9 steht der gesamte Stack zur Verfügung, wird aber nicht standardmäßig implementiert. Auf einem Server (Ihr Hauptserver mit bm-core oder ein dedizierter Monitoring-Server) muss das bm-tick-full-Paket installiert werden.
Dieses Paket wird den gesamten TICK-Stack bereitstellen (den wir in unsere Ablagen integriert haben, um die verwendeten Versionen zu kontrollieren). Auf jedem Server Ihrer BlueMind-Anlage muss bm-tick-node installiert werden. Wenn Sie dies vor dem Wechsel zu 3.5.9 tun, wird sich der Aktualisierungsassistent um alles kümmern. Andernfalls ist es besser, nach dem Neustart die Konfiguration des gesamten Stack zu forcieren:
curl -H „X-Bm-ApiKey: $(cat /etc/bm/bm-core.tok)“ -XPOST http://localhost:8090/internal-api/tick/mgmt/_reconfigure
ausgehend von Ihrem bm-core-Server.
Java-Agent
Die aufmerksamsten Systemverwalter werden feststellen, dass die Java-Prozesse von BlueMind mit einer zusätzlichen Option gestartet werden:
/usr/lib/jvm/bm-jdk/bin/java -Dlogback.configurationFile=/etc/bm/local/bm-core.log.xml -Dio.netty.native.workdir=/var/lib/bm-core/work -Xloggc:/var/log/garbage-collector/bm-core/gc.pause.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=4 -XX:GCLogFileSize=4M -XX:+PrintGCApplicationStoppedTime -server -Xms812m -Xmx812m -Xss256k -XX:+UseCompressedOops -XX:MaxDirectMemorySize=812m -XX:+UseG1GC -XX:MaxGCPauseMillis=500 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log -Djava.net.preferIPv4Stack=true -Dnet.bluemind.property.product=bm-core -javaagent:/var/lib/bm-metrics-agent/bm-metrics-agent.jar -Djava.awt.headless=true -Dosgi.noShutdown=true -Duser.timezone=GMT -cp /usr/share/bm-core/plugins/org.eclipse.equinox.launcher_1.3.201.v20161025-1711.jar org.eclipse.equinox.launcher.Main -registryMultiLanguage -debug -application net.bluemind.application.launcher.coreLauncherDank dieses Agenten, der mit unseren virtuellen Computern verbunden ist, können wir unsere Anwendungsmetriken gegenüber Telegraf präsentieren. Wie geht er vor?
Er öffnet für jeden JVM ein Unix-Socket in /var/run/bm-metrics:
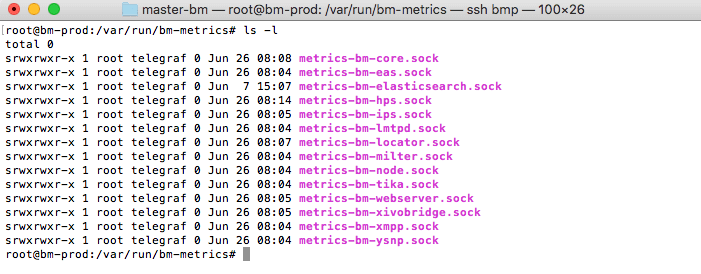
Diese Unix-Sockets werden von Telegraf abgefragt, um die Metriken jeder Komponente zu erhalten:
curl –unix-socket /var/run/bm-metrics/metrics-bm-lmtpd.sock http://bm/metricsDas ergibt in vereinfachter Version:
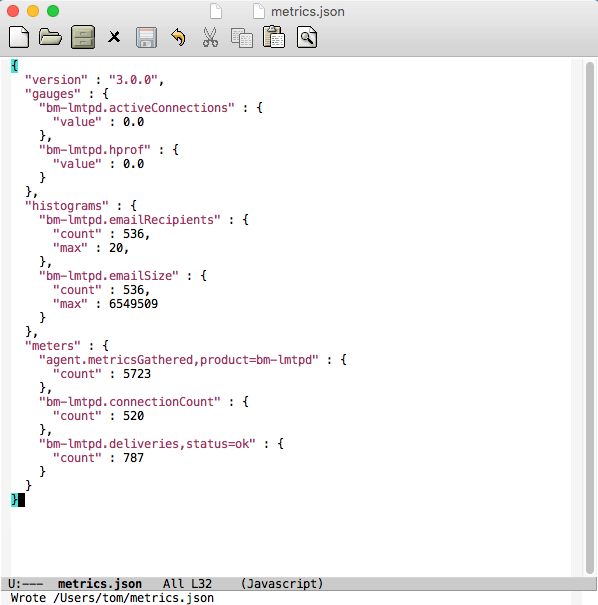
Diese Daten werden alle 10 Sekunden von Telegraf abgefragt und …
Dashboards!
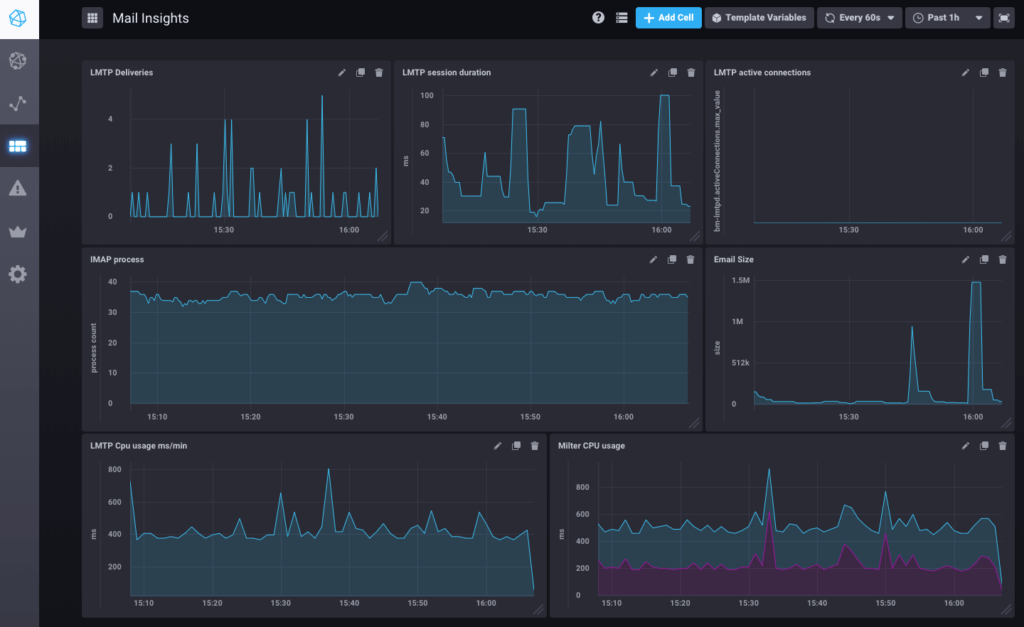
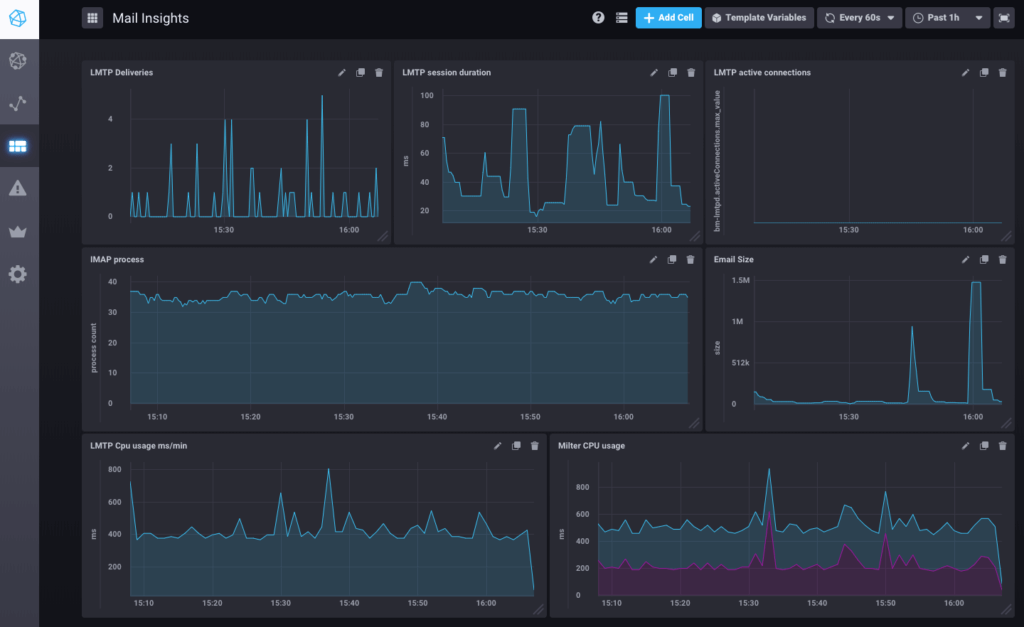
Dies ist ein Beispiel für ein in BlueMind 3.5.9 vorkonfiguriertes Dashboard zum Nachrichtenfluss.
Es stehen aber noch zahlreiche weitere Dashboards zur Verfügung: System (Datenträger, Auslastung, Netzwerkdatenverkehr), postgresql (QPS, Nutzung freigegebener Puffer), nginx.
Die Daten werden in einem Zeitfenster von 7 Tagen historisiert; also kein Geheimnis mehr um die Festplatte, die 2 Stunden vor der Meldung eines Vorfalls noch voll war.
Alerting
Es ist ganz in Ordnung, die Zahl der aktiven IMAP-Prozesse zu kennen. Noch besser ist es, sie mit dem konfigurierten Höchstwert zu vergleichen.
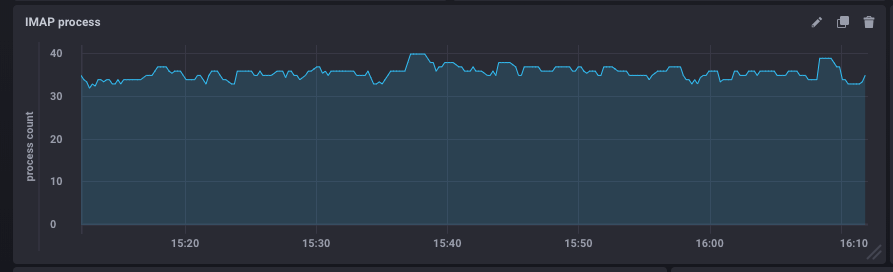
Diese Metrik wird permanent von Kapacitor beobachtet (das imap-connections-Skript ist von BlueMind konfiguriert), um die Anzahl der Prozesse zu einem bestimmten Zeitpunkt mit der in BlueMind konfigurierten Anzahl zu vergleichen.

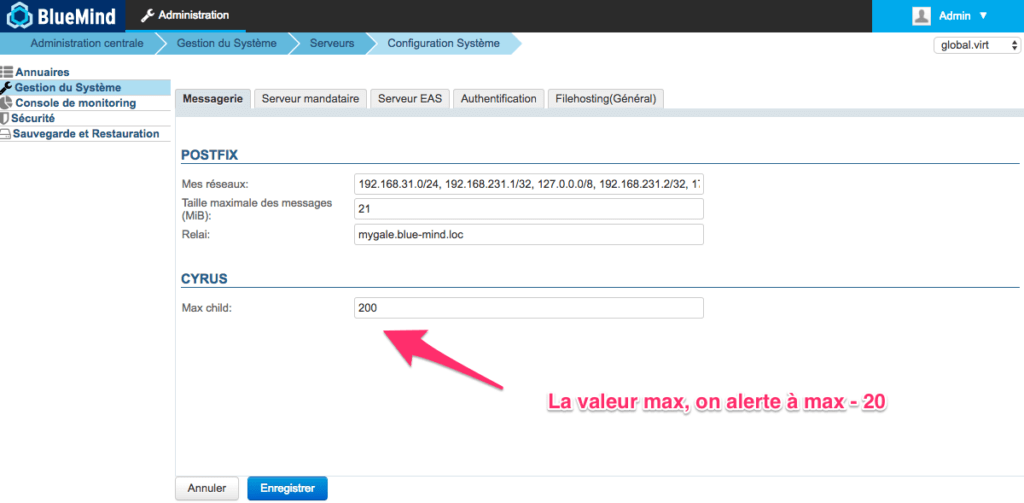
Diese Alerts werden auf der Startseite des monitoring/tick/ Ihres BlueMind-Systems mit dem Passwort des Installationsassistenten angezeigt.
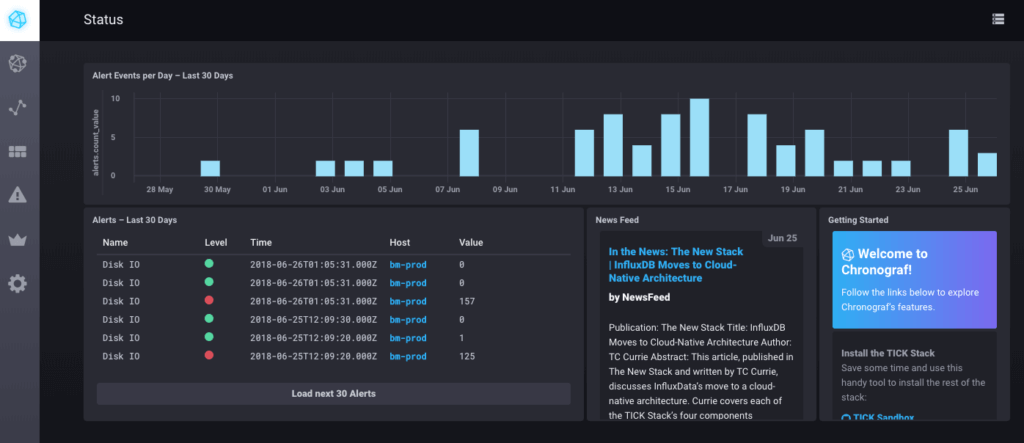
Hinweise
Die Alerts führen logischerweise zu Annotationen, mit denen wir auf unseren grafischen Darstellungen bestimmte Zeitpunkte (oder Zeiträume) verfolgen können.
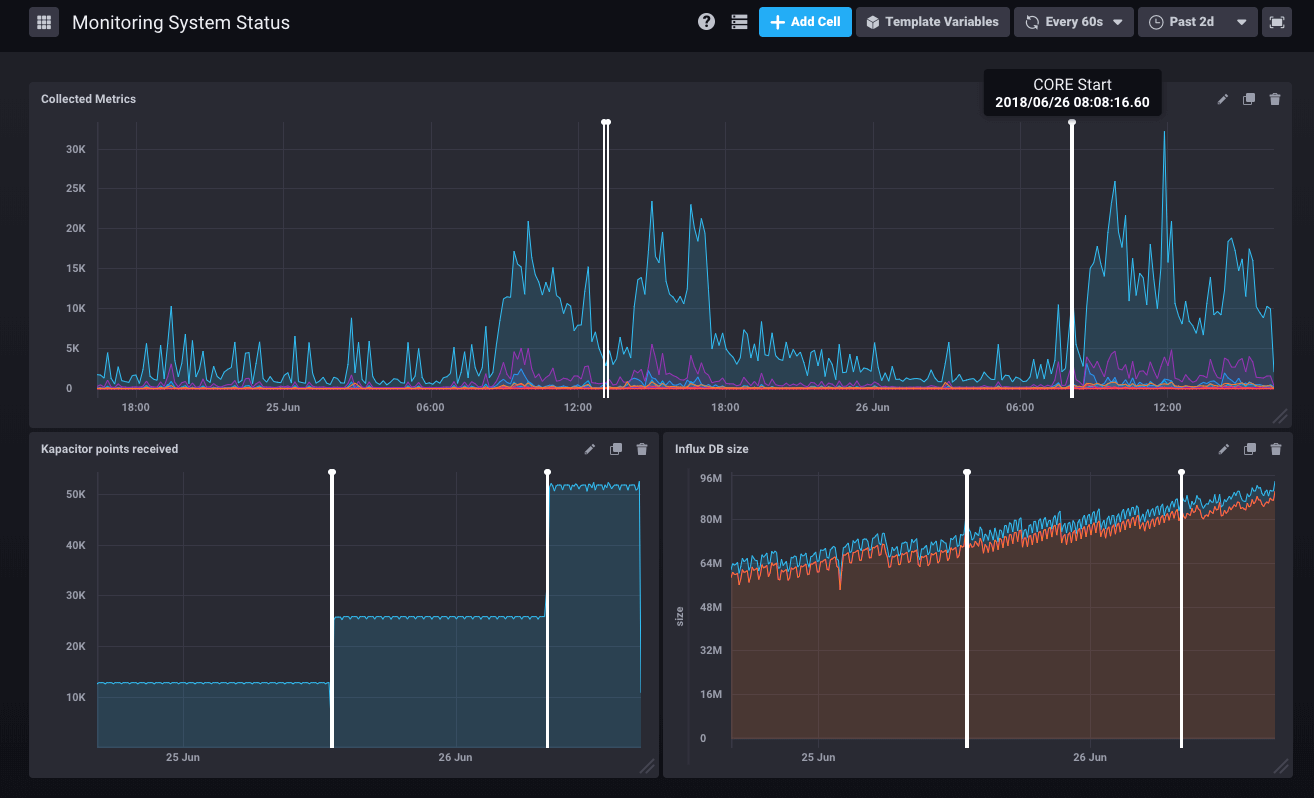
Wenn der Core-Server von einem Systemverwalter neu gestartet wurde, wird dies durch das Monitoring archiviert und auf allen grafischen Darstellungen angezeigt:
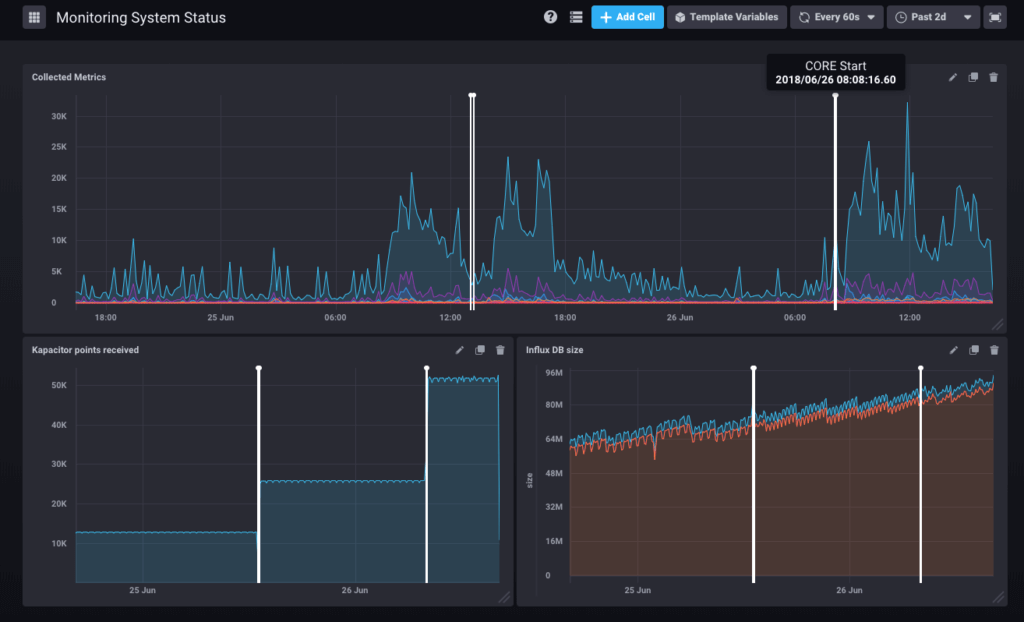
Die programmierten Aufgaben, die auf Ihrem System ablaufen, werden ebenfalls in die grafischen Darstellungen integriert, wenn sie länger als 30 Sekunden dauern. Künftig wird es möglich sein, zweifelsfrei zu diagnostizieren, ob die von den Benutzern wahrgenommenen Verlangsamungen auf einen Sicherungsvorgang oder auf den Import eines Verzeichnisses zurückzuführen sind.
Die Fortsetzung
Von unserem Produkt werden zahlreiche Metriken aufgezeichnet, aber noch nicht alle werden in den grafischen Darstellungen oder Alerting-Skripten ausgewertet. Die Dashboards und Alerting-Skripte können BlueMind über Plug-Ins hinzugefügt werden, und die nächsten Versionen dürften neue davon enthalten und „Selbstheilungs“-Funktionen vorschlagen (wenn ein bestimmtes Problem auftritt und die Lösung bekannt ist, wird sie automatisch angewendet).