Un système BlueMind ou un serveur de messagerie en général est un système complexe. Il intègre de nombreux composants avec des rôles bien définis mais parfois obscurs. Lorsque une panne se produit ou que des dysfonctionnements sont constatés, il est souvent complexe d’en trouver la cause.
Une panne du système de messagerie est souvent source de panique car le service est critique pour la majorité des utilisateurs. Des mesures d’urgence sont alors prises, qui conduisent souvent à des redémarrages qui solutionnent (parfois) le problème mais vont rendre l’analyse post-mortem particulièrement complexe.
L’existant
Un système BlueMind, composé de nombreux services et de nombreuses machine virtuelles Java, essaie le plus souvent de ne pas mourir en silence.
On va trouver :
• Des fichiers /var/log/java_pid1234.hprof ; des dumps mémoires générés automatiquement lorsque le système rencontre un manque de mémoire
• Des fichiers de logs, très nombreux, où l’on va trouver des vilaines choses comme des index elastiscsearch qui nous disent « disk high watermark reached, disabling shards » (le disque dur est plein)
Dans ces différents cas, le problème ne sera pas pris en compte tout de suite, et un redémarrage ou un nettoyage du disque va avoir lieu avant qu’une anomalie ne soit remontée pour analyse.
Laisser un disque dur se remplir quand on gère un système n’est pas un fait d’arme très glorieux. On arrive à la situation suivante : l’administrateur système nettoie le disque dur, puis déclare une anomalie pour indiquer que la recherche n’est plus fonctionnelle.

Ce petit mensonge est problématique, mais ce qui nous intéresse, c’est d’empêcher la situation de se produire.
La supervision
Les systèmes de supervision existent, mais leur déploiement était jusqu’à maintenant laissé à la charge des personnes supervisant des installations BlueMind. La supervision des systèmes Java est un sujet assez complexe et les métriques généralistes ne sont ni intéressantes ni parlantes.
Avec BlueMind 3.5.9, nous avons intégré un stack complet de métriques, alerting et de visualisation de l’état de la plateforme.
Notre ADN étant open-source, nous nous sommes tournés vers une solution open-source : la TICK stack (Telegraf, Influxdb, Chronograf, Kapacitor) http://influxdata.com. Un agent telegraf est installé sur chaque nœud de votre installation. Telegraf transmet ces données à Influxdb, Kapacitor les analyse pour produire des alertes et Chronograf affiche des tableaux de bord pour aider à anticiper les problèmes.
Notre intégration
Pour la 3.5.9 toute la stack est disponible mais n’est pas déployée par défaut. Sur un serveur (votre serveur principal, avec bm-core, ou un serveur de supervision dédié) il faut installer le paquet bm-tick-full.
Ce dernier va déployer toute la stack TICK (que nous avons intégré dans nos dépôts pour contrôler les versions utilisées). Sur chaque serveur de votre installation BlueMind, il faut installer bm-tick-node. Si vous faites cela avant le passage en 3.5.9, l’assistant de mise à jour va s’occuper de tout. Sinon il est préférable après redémarrage de forcer la configuration de toute la stack :
curl -H « X-Bm-ApiKey: $(cat /etc/bm/bm-core.tok) » -XPOST http://localhost:8090/internal-api/tick/mgmt/_reconfigure
depuis votre serveur bm-core.
Agent Java
Les administrateurs les plus attentifs vont remarquer que les processus Java de BlueMind sont lancés avec une option supplémentaire :
/usr/lib/jvm/bm-jdk/bin/java -Dlogback.configurationFile=/etc/bm/local/bm-core.log.xml -Dio.netty.native.workdir=/var/lib/bm-core/work -Xloggc:/var/log/garbage-collector/bm-core/gc.pause.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=4 -XX:GCLogFileSize=4M -XX:+PrintGCApplicationStoppedTime -server -Xms812m -Xmx812m -Xss256k -XX:+UseCompressedOops -XX:MaxDirectMemorySize=812m -XX:+UseG1GC -XX:MaxGCPauseMillis=500 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/log -Djava.net.preferIPv4Stack=true -Dnet.bluemind.property.product=bm-core -javaagent:/var/lib/bm-metrics-agent/bm-metrics-agent.jar -Djava.awt.headless=true -Dosgi.noShutdown=true -Duser.timezone=GMT -cp /usr/share/bm-core/plugins/org.eclipse.equinox.launcher_1.3.201.v20161025-1711.jar org.eclipse.equinox.launcher.Main -registryMultiLanguage -debug -application net.bluemind.application.launcher.coreLauncher
C’est cet agent, attaché à nos machines virtuelles, qui nous permet d’exposer nos métriques applicatives à Telegraf. Que fait-il ?
Il ouvre un socket unix dans /var/run/bm-metrics, pour chaque JVM :
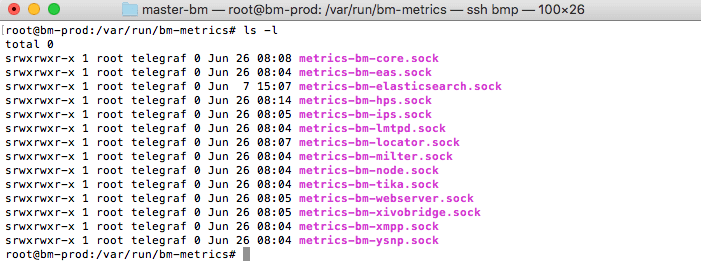
Ces sockets unix sont interrogés par Telegraf pour obtenir les métriques de chaque composant :
curl –unix-socket /var/run/bm-metrics/metrics-bm-lmtpd.sock http://bm/metrics
Qui nous donne en version simplifiée :
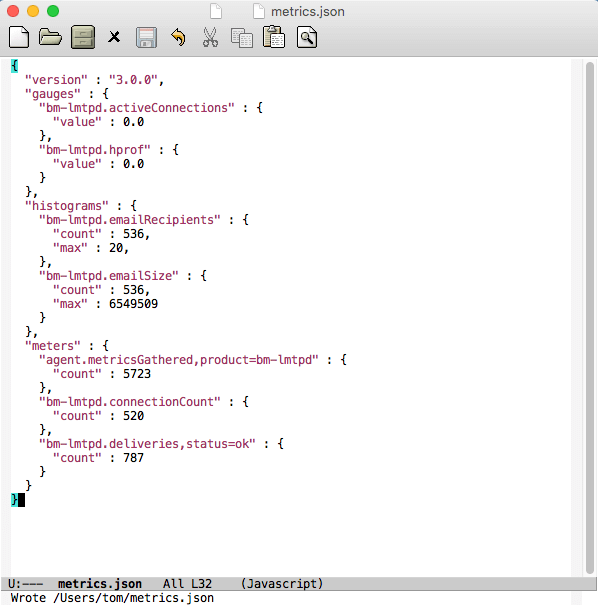
Ces données vont être consommées par Telegraf toutes les 10 secondes et…
Dashboards !
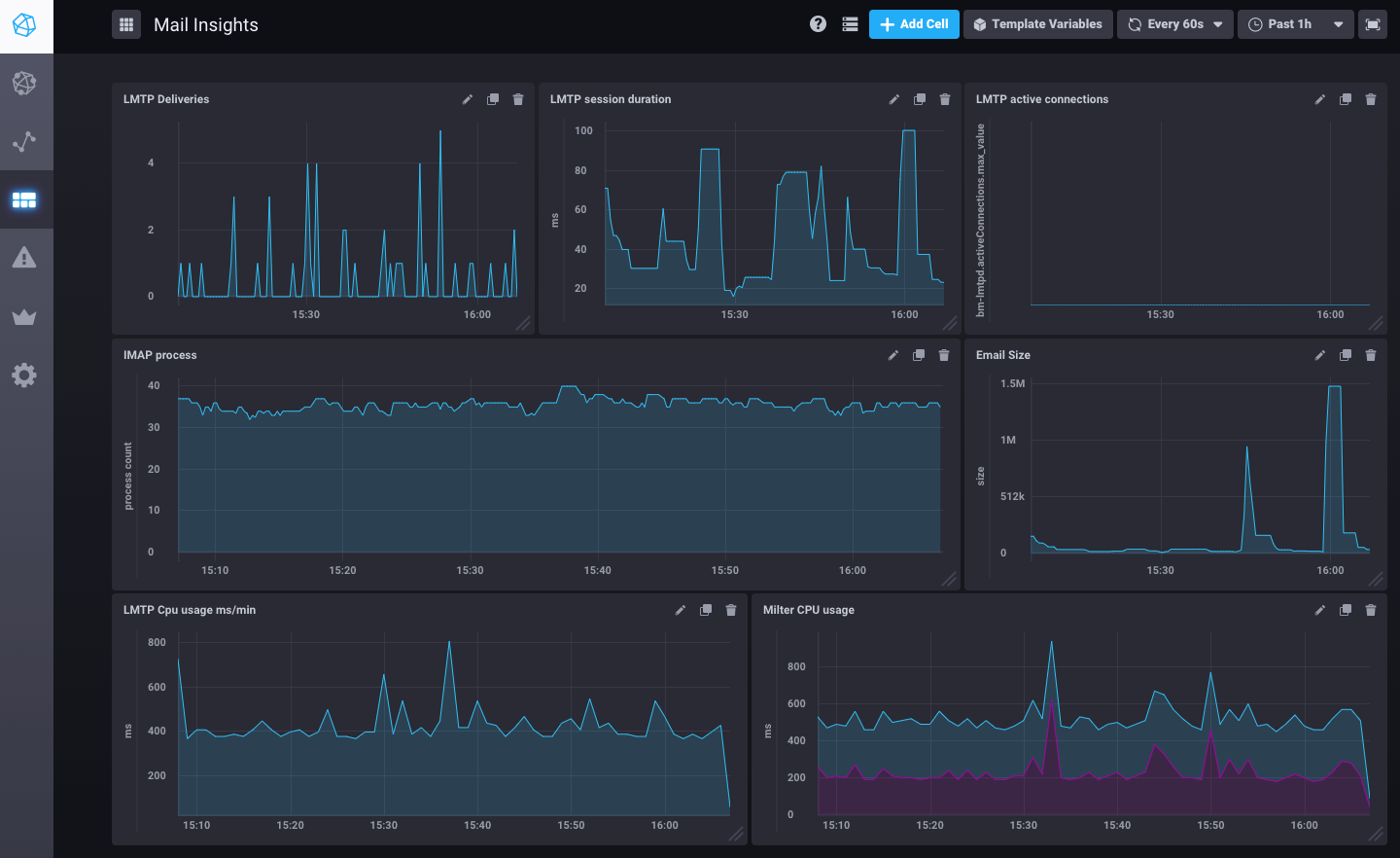
Ceci est un exemple de tableau de bord sur le flux de mail pre-configuré dans BlueMind 3.5.9.
Mais de nombreuses autres métriques sont disponibles : système (disques, charge, trafic réseau), postgresql (QPS, shared buffers usage), nginx.
Les données sont historisées sur une fenêtre de 7 jours, donc plus de mystère sur le disque dur qui était encore plein 2 heures avant de remonter un incident.
Alerting
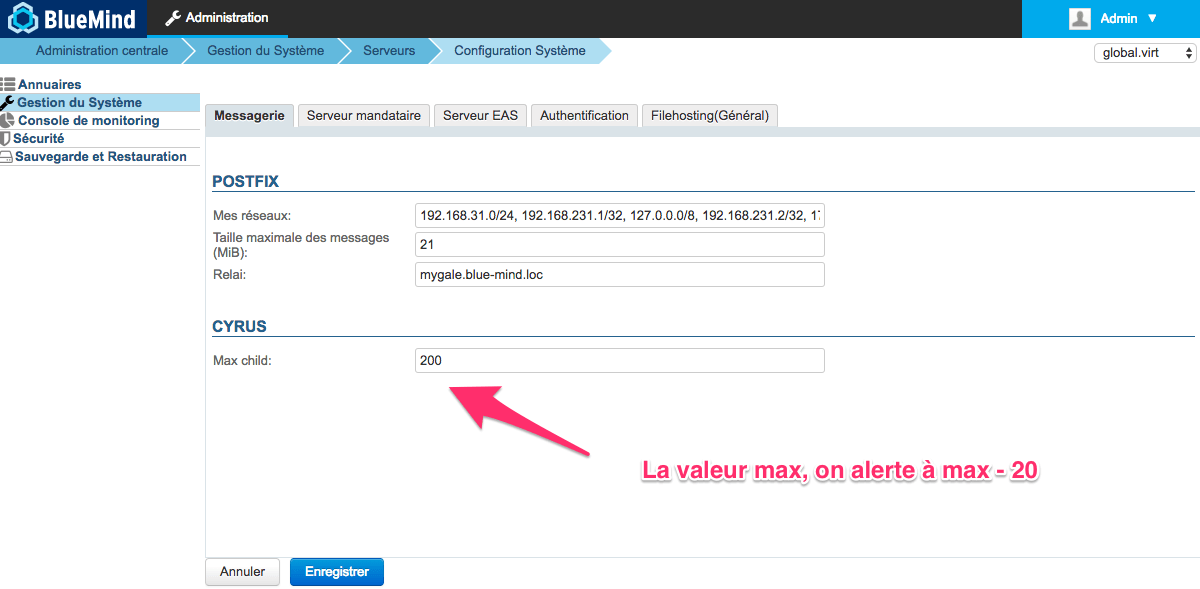
Connaître le nombre de processus IMAP actifs, c’est bien. Le comparer avec le maximum configuré c’est mieux.
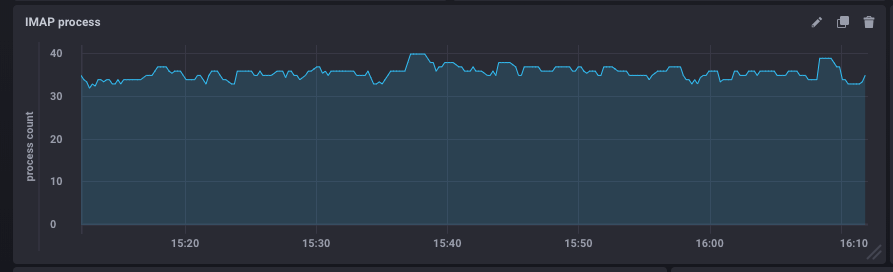
Cette métrique est observée en permanence par Kapacitor (le script imap-connections est configuré par bluemind) pour comparer le nombre de process à un instant avec celui configuré dans BlueMind.
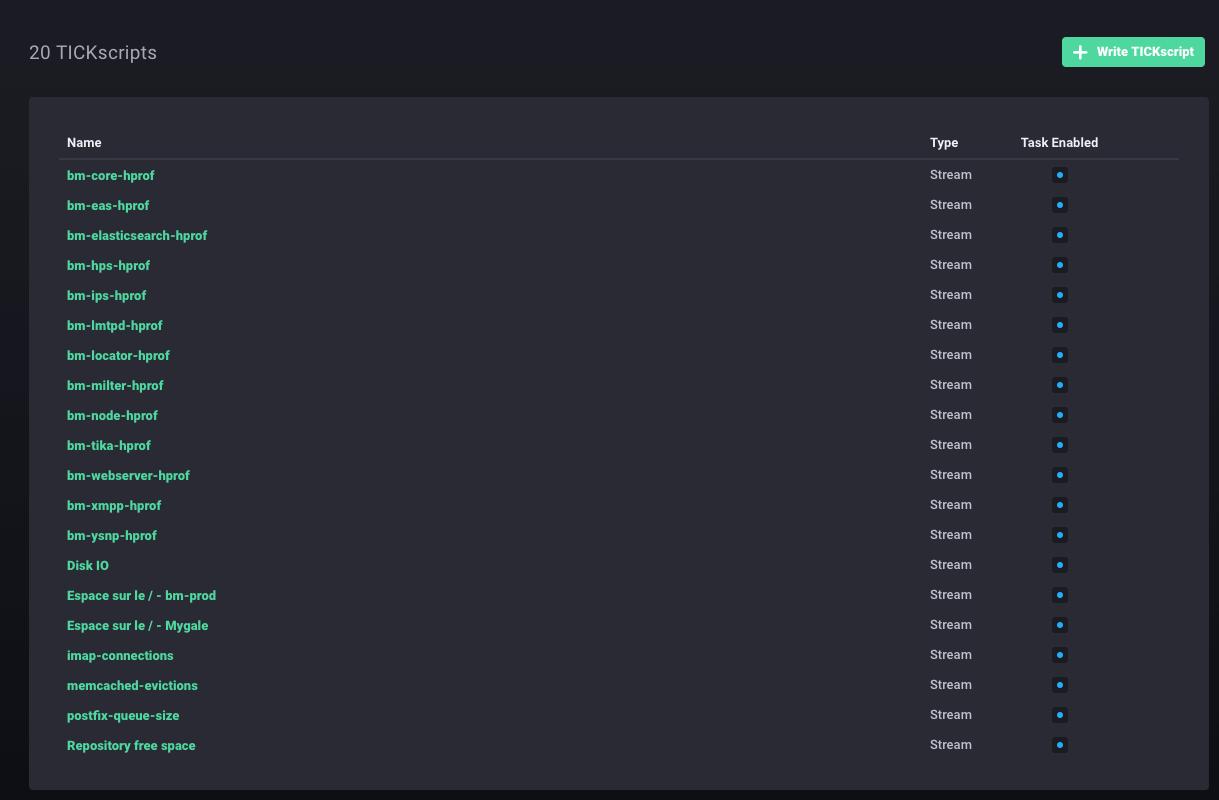
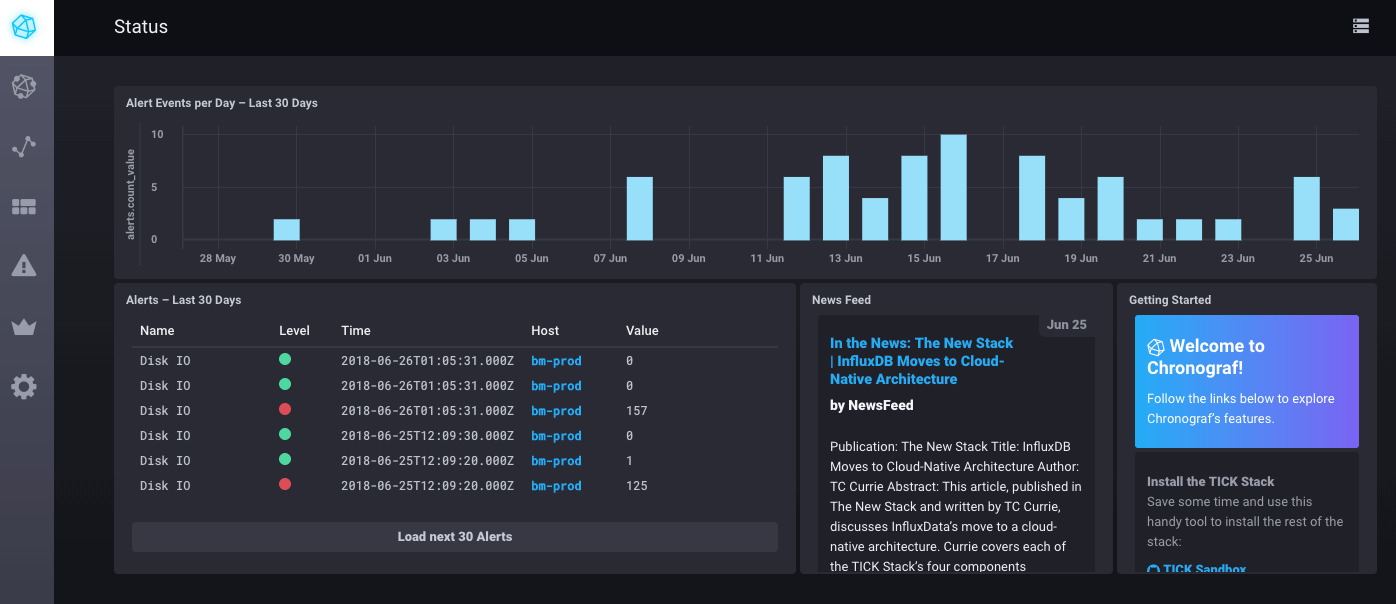
Ces alertes sont visibles sur l’accueil du monitoring/tick/ de votre BlueMind avec le mot de passe de l’assistant d’installation.
Annotations
En corrolaire des alertes viennent les annotations, qui nous permettent de pointer des points dans le temps (ou des plages de temps) sur nos graphes.
Si le Core est redémarré par un administrateur, la supervision l’archive et le montre sur tous les graphes :
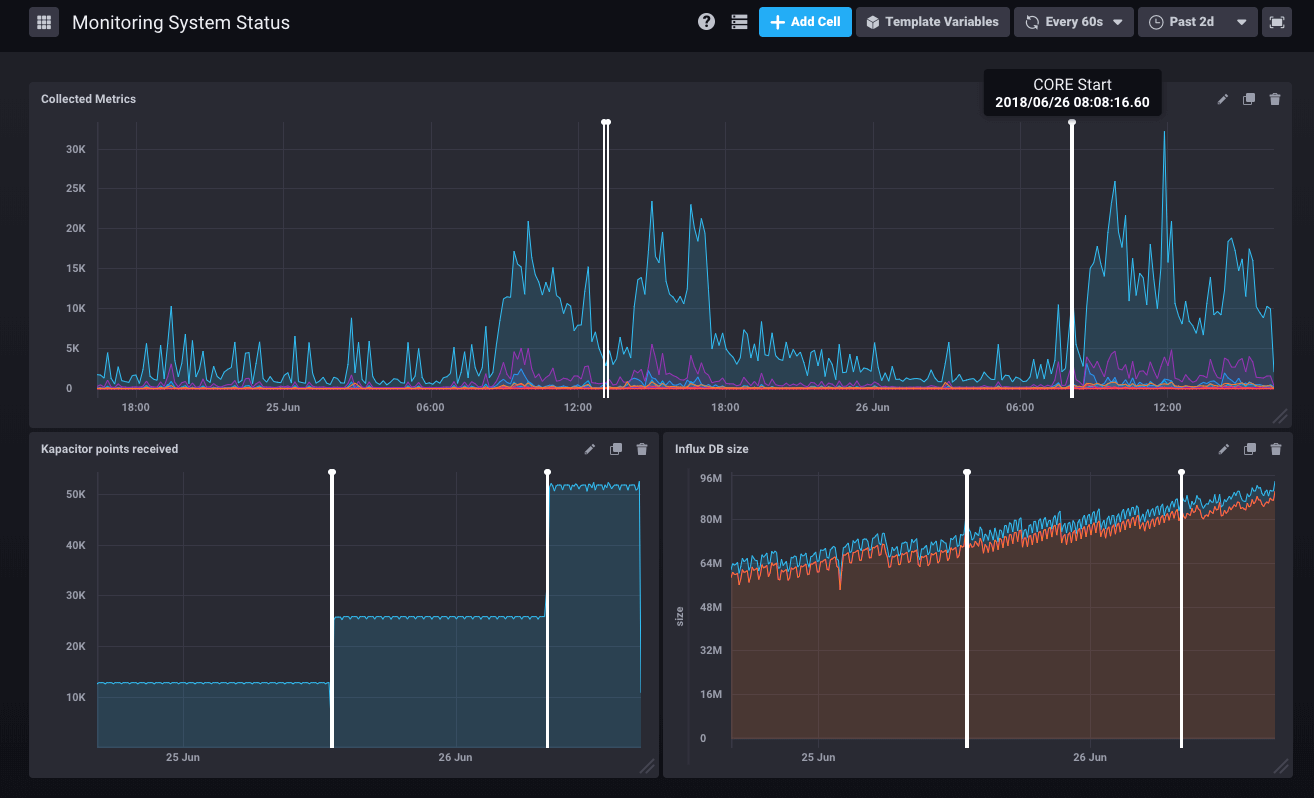
Les tâches programmées qui s’exécutent dans votre système sont aussi intégrées sur les graphes dès qu’elles prennent plus de 30 secondes. Plus de doute désormais pour diagnostiquer que les lenteurs ressenties par les utilisateurs sont dues à une sauvegarde ou un import d’annuaire.
La suite
De nombreuses métriques sont enregistrées par notre produit mais toutes ne sont pas encore exploitées dans des graphes ou des scripts d’alerting. Les dashboards et scripts d’alerting peuvent être ajoutés à BlueMind via des plugins et les prochaines versions devraient en amener de nouveaux et proposer des fonctions de « self healing » (quand tel problème survient, la solution est connue et donc appliquée de manière automatique).



