The first half of 2020 has come with its share of surprises. Many of us have experienced remote work for the first time, changed work habits and everyday tools and altered the way we previously organised our activities to online collaboration. Email has more than ever risen as the oxygen of digital communications.
From the point of view of a software publisher whose core activity is the constant improvement of its solution, work never stops. We’ve not slackened for a second to carry out major projects and pursue and speed up our solution’s consolidation. We would have loved to show you these evolutions at a BlueMind Summit in 2020, but the current context is encouraging us to move it to 2021.
The evolution of technical and software architecture, staying at the state-of-the-art, optimising performance, resolving technical debt, adding new tools and interfaces, enriching existing tools and our ecosystem are all part of the BlueMind solution’s consolidation efforts. Here are a few of the most recent or ongoing projects that account for 70% of our day-to-day.
Thunderbird: anticipating evolutions
Thunderbird follows Firefox’s development through a shared code base as well as broad extension changes. The change to the extensions’ structure and how they interact with Thunderbird began with the earlier version 68, but it is now, with version 78, that the changes have become truly effective. Legacy extensions have been replaced by WebExtensions. For BlueMind, this means that we’ve had to recode our extension almost entirely so that it meets Thunderbird’s new requirements seamlessly.
Thunderbird 78 has just been released although with no automatic update yet. This will come in due time to give developers time to adapt their extensions to all the changes. BlueMind has been working on this already and will very soon offer the connector for Thunderbird’s new version.
.
Object storage and optimisation
In environments with large storage requirements, using object storage has many advantages.
Read our article about object storage here.
Many people believe that adding an S3 interface (or Swift, or other) is all you need to implement an object storage solution on your cloud. It’s not! Object storage involves:
- Redesigning how the data is managed and handled, otherwise the solution may be completely useless. This has been one of the major projects in the development of the BlueMind/Cyrus IMAP object storage.
- An object storage solution that meets the email system’s performance requirements.
- Developing usage and stress simulation tools to validate different usage and operating scenarios.
Thanks to these tools, we’ve observed that S3 server access latency under operating conditions isn’t always optimal. The main factor that visibly impacts performance for users is object access latency. Latency is the time between the moment access to an object is requested and the moment the full message is received. Latency depends on network access speed as well as the object storage system’s inherent latency.
Below is a functional diagram of object storage bricks:
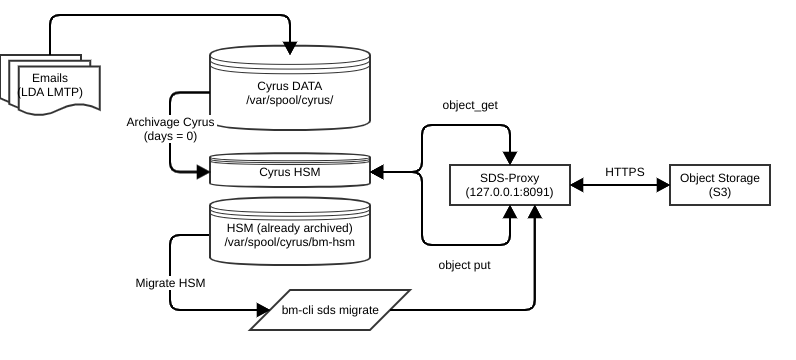
When a thick client makes an email synchronisation query to the BlueMind server, the Cyrus IMAP server retrieves the messages sequentially (i.e. one after the other). With a 100ms message access latency, retrieving 30 messages will take at least 100 * 30 = 3000ms, i.e. 3 seconds.
To reduce the effects of access latency on large objects, we’ve developed a system that downloads messages in parallel. With this system and the same 100ms network latency, a user’s access to 30 messages will no longer take 3000ms but 100ms. Up to 300 messages can be downloaded simultaneously.
To help keep an eye on latencies perceived by BlueMind, we’ve added a series of metrics and a dashboard to the TICK monitoring suite.
We’ve also added a functionality for administrators to find out what an imap backend is doing. This helps quickly see whether a user is using too many connections or understand why a process is consuming many inputs or outputs. The name of the imap process changes automatically depending on what the process does.
Example:
```cyrus 3476 0.3 0.2 63776 16480 ? S 14:44 0:01 imap: [192.168.132.240] laurent.coustet@s3.loc s3.loc!user.laurent^coustet.INBOX.Test move Idle```
.
Email/S3 Benchmarking Tool
To step things up and validate object storage infrastructure, we’ve developed a tool that simulates email server load on the object storage to measure its performance. This open-source tool is available on github.
Unlike other benchmarking tools, we’ve tried to simulate an overall email server load, not just raw transfer speed. We measure access latency as well as available bandwidth with real emails from an open distribution list such as Linux Kernel Mailing List (LKML).
Below is an example of performance measurement, with a network access latency of 5 milliseconds. (Toulouse -> Roubaix — 900km).
```+--------+--------------+-----+-----+-----+-----+-----+------+------+| TEST | THROUGHPUT | AVG | P25 | P50 | P75 | P90 | P99 | MAX |+--------+--------------+-----+-----+-----+-----+-----+------+------+| PUT 1 | 27.73 KiB/s | 290 | 167 | 222 | 333 | 562 | 1030 | 5408 || GET 1 | 164.48 KiB/s | 49 | 32 | 38 | 47 | 72 | 252 | 2260 || PUT 4 | 122.93 KiB/s | 261 | 154 | 205 | 300 | 505 | 829 | 2597 || GET 4 | 692.30 KiB/s | 46 | 30 | 36 | 45 | 65 | 247 | 1574 || PUT 8 | 243.18 KiB/s | 264 | 159 | 211 | 305 | 493 | 777 | 2485 || GET 8 | 1.34 MiB/s | 43 | 28 | 35 | 44 | 66 | 199 | 1319 || PUT 16 | 423.21 KiB/s | 302 | 176 | 241 | 373 | 598 | 819 | 2668 || GET 16 | 2.44 MiB/s | 50 | 29 | 37 | 50 | 76 | 259 | 1894 || PUT 32 | 841.70 KiB/s | 304 | 169 | 232 | 372 | 612 | 992 | 2119 || GET 32 | 4.28 MiB/s | 45 | 26 | 34 | 45 | 74 | 197 | 2267 || DEL 8 | 0.03 KiB/s | 305 | 170 | 243 | 391 | 600 | 791 | 1861 |+--------+--------------+-----+-----+-----+-----+-----+------+------+```
You can see that the best throughputs are achieved with 32 simultaneous connections to the storage server and download latency remains constant, regardless of transfer throughput.
You should note, however, that message access latency is 45 milliseconds on average, despite a network latency of only 5 milliseconds. This is why it’s important to use measuring tools to make sure that object storage is configured properly when used as email storage.
.
MAPI: Natively Outlook Compatible
Being Outlook compatible means:
- Integrating the MAPI protocol, the protocol – or rather series of protocols – developed by Microsoft for Exchange.
- Handling Microsoft’s highly complex data model – which is based on a property/value principle. Just the list of known Exchange properties has 376 pages of specifications… and this list is only one document out of 130 publicly available specifications. Lovers of metaobjects and binary formats that fluctuate depending on versions and contexts, welcome!
- Adapting our solution to respond effectively to Outlook queries through a REST API. This has entailed far-reaching changes to the BlueMind architecture, including for email information management and storage to be able to respond to Outlook queries, which are database/property queries, with no relation to message transactions or IMAP standards.
This herculean task, which only BlueMind has been able to complete, resulted in the release of the fully Outlook-compatible BlueMind v4 in 2019.
Like with every new version release, this has been a reality check! What works well “in vitro” sometimes has its “in vivo” surprises — and new scenarios. 2020 has been – and still is – a year of finishing touches and adaptation to “real-life production situations”.
Our MAPI implementation has led to improved Outlook functional coverage and more diagnostic, monitoring and operating tools. Our teams continue to be hard at work to consolidate and fine-tune BlueMind v4.
 Data compliance
Data compliance
.
Update Tool
For better server load management and reduced service downtime, BlueMind has had to undergo significant architecture changes to enable more email information to be stored and exposed.
To upgrade a BlueMind install to version 4, the update tool has to go through every message for BlueMind to ingest their contents. Reading all the messages of an install is a time-consuming and costly operation.
Additionally, upgrading to version 4 requires messages to be re-indexed. This also is extremely time consuming. For an update to be performed within a timeframe that’s compatible with production demands and to avoid excessive service downtime, we’ve upgraded our update tools so that they are capable of pre-processing these time-consuming operations ahead of the changeover without interrupting production service.
As a result, when an update process detects pre-processed data, it no longer needs to go over this data again. Service downtime is reduced to a minimum and the version upgrade doesn’t take any longer than any other major update.
.
Zimbra to BlueMind Migration Tool
We’ve developed a tool to facilitate the migration from a Zimbra infrastructure to a BlueMind install. This tool is written in Python using exclusively open APIs (programming interfaces) available in BlueMind and Zimbra.
Our migration tool doesn’t just synchronise emails, it also integrates all essential functionalities needed for a successful migration. For instance, it migrates Zimbra users to BlueMind while keeping their contact information, “Out of Office” settings and forwarding to external email addresses.
Passwords can be an issue. This is why we’ve incorporated into BlueMind the management of all the types of passwords managed by Zimbra so that no passwords need to be reset when changing over from Zimbra to BlueMind.
The tool also migrates users’ calendars and address books with their associated privileges and shares. Calendar settings are directly synchronised on the user’s calendar and no manual subscription is required. We’ve also incorporated the management of shares for calendars and address books.
Video from our webinar “Migrating from Zimbra to BlueMind”
Migrating from a Zimbra to a BlueMind server can be done in several stages over time. To do this we’ve integrated the admin tools required to synchronise data in increments. That way you can start a synchronisation and check that it works properly for a few users and later take up the synchronisation to keep the Zimbra and BlueMind data on par. The increment speeds up processing time and reduces the number of logs the tool produces which limits checking time to a minimum.
Because the bm-migrator tool uses public APIs, it can be run on any machine with access to the Zimbra and BlueMind servers.
We’ve made every effort to keep the tool’s installation straightforward. A simple executable file contains the entire tool (except for imap-sync which has to be installed manually before messages are synchronised).
For our developer friends, we’ve incorporated a shell to facilitate extra script writing for specific needs – that way they can use all BlueMind and Zimbra directives and data. For example, if a migration is interrupted because of invalid or incoherent data, the data can be edited live and they can tell the migration tool to resume the migration from that point.
.
BM-Cli: BlueMind administration in command line
BM-Cli is BlueMind’s command line interface. It lets you automate admin operations and makes day-to-day management easier.
Why a CLI you ask? We’d be tempted to reply that the people who can’t see the point of a command line interface probably don’t read much about administration issues. Today, most BlueMind operations are carried out through a web-based admin console.
But an admin console has a limited number of actions and capabilities. A CLI helps complement the admin console as it lets you script operations, extract data for specific listing and processing, automate action sequences, perform operations from external programs…
BM-Cli is an integrated tool that uses APIs to automate a wide range of actions, perform multiple repairs (multithread), with no need to code.
We are constantly adding to the BlueMind CLI to make it more comprehensive, allow operations on all types of data generated by BlueMind and automate more tasks.
Watch our video about BM-Cli and how to install it.
.
To be continued…
End of part one! Part two will be ready in August to bring you an update about the following tasks:
- Improvements to the calendar
- Progress on the new webmail solution
- Baseware maintenance and update
- Overall performance improvements
- Maturity of TICK diagnostic tool